BAYESIAN BOOTSTRAP AND TRADITIONAL BOOTSTRAP
Let’s compare Bayesian bootstrap with traditional bootstrap by applying them to regression coefficients of a linear regression. We analyze how vehicle price (price) and repair records (rep78) affect fuel efficiency (mpg) by using the auto dataset.
We first perform traditional bootstrap by using the existing bootstrap prefix and then Bayesian bootstrap by using the new bayesboot prefix. We specify the rseed(111) option with both for reproducibility.
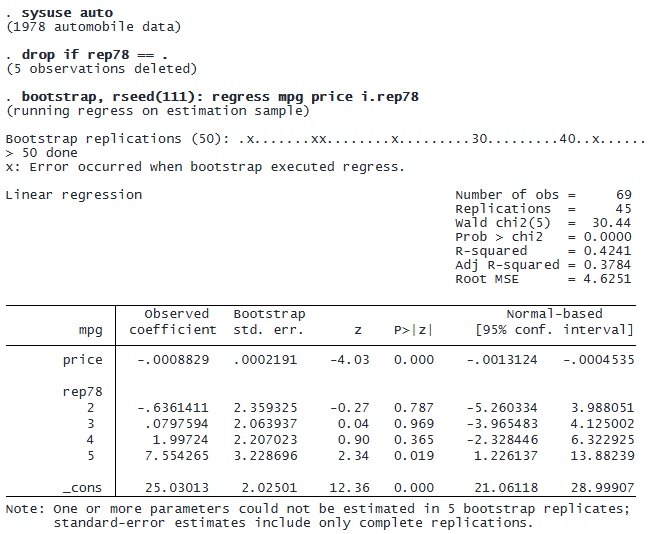
Now let’s perform the same analysis using Bayesian bootstrap. We also specify bayesboot‘s generate() option to save the generated importance weights in the new variables iw1 through iw50 for later comparison.
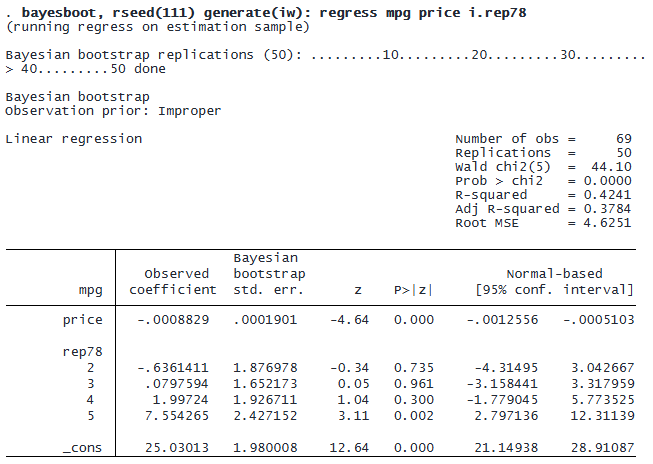
Although both methods lead to similar overall conclusions, an advantage of Bayesian bootstrap can be seen from the replication output. Notice the “x” markers in the traditional bootstrap results. These markers indicate that replications could not be computed, leading to missing values for regression coefficient estimates in those replications. This could happen because of perfect collinearity or because some of rep78‘s categories do not have any observations to compute a coefficient. In contrast, bayesboot completes all 50 replications without errors.
This improved stability stems from the use of continuous weights by Bayesian bootstrap, as opposed to the discrete resampling of traditional bootstrap. The continuous weighting approach maintains greater numerical stability by avoiding the perfect collinearity that sometimes occurs with discrete resampling.
INCORPORATING PRIOR INFORMATION
One of Bayesian bootstrap’s key advantages is the ability to incorporate domain knowledge by specifying priors for observations when you have information about the relative importance or reliability of observations.
© Copyright 1996–2026 StataCorp LLC. All rights reserved.
Below, we explore how different prior values affect estimation precision and statistical significance by using the priorpowers() option to modify the default prior.
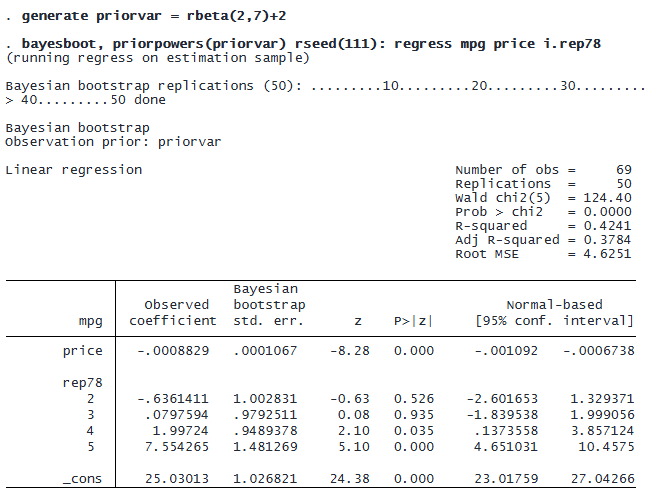
Looking at the coefficient for 4.rep78, we see that its confidence interval includes 0 with default priors, whereas it does not with our custom priors. This occurs because higher prior values represent stronger belief in the representativeness of the dataset, resulting in narrower confidence intervals.
BAYESBOOT AS A WRAPPER
The bayesboot command is a convenience wrapper that combines the following two features:
- The rwgen bayes command, which generates importance weights based on the Bayesian bootstrap method
- bootstrap‘s iweights() option, which applies these weights during estimation
We can replicate the results from bayesboot in the previous example by specifying the following two commands.
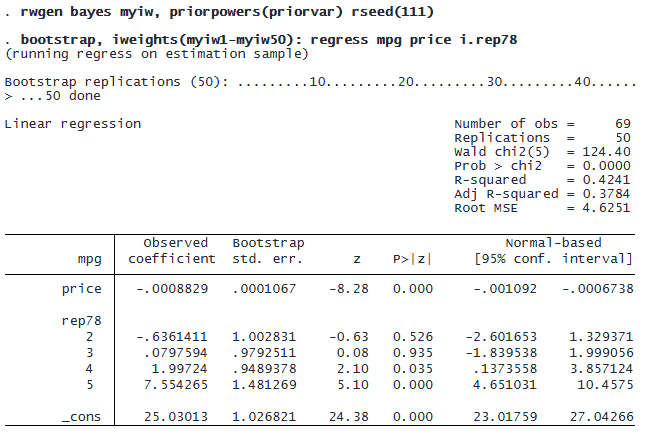
THE IMPACT OF CUSTOM PRIORS
To understand how custom priors affect our analysis, let’s compare the distributions of the default and custom weights for the first replicate:

The summary statistics reveal important differences in the distributions of weights. Although both sets maintain the same mean (1/69 = 0.0144928), the custom weights based on our higher prior values show substantially lower variability. This difference in variability has a direct impact on our regression results, as we saw earlier.