Treatment-effects estimation using lasso
You use treatment-effects estimators to draw causal inferences from observational data. Perhaps you want to estimate the effect of a drug regimen on blood pressure, the effect of a surgical procedure on mobility, the effect of a training program on employment, or the effect of an ad campaign on sales.
You use lasso inferential estimators when you are interested in inference on a few covariates while controlling for many other potential covariates. (And when we say many, we mean hundreds, thousands, or more!)
You can now use these estimators simultaneously. With the new telasso command, you can estimate treatment effects while controlling for many potential covariates.
For example, you can type
. telasso (y1 x1-x100) (treat w1-w100)
to estimate the effect of the binary treatment treat on the continuous outcome y1 while controlling for predictors x1 through x100 in the outcome model and for w1 through w100 in the treatment model. The obtained estimates benefit from robustness properties of both the treatment-effects estimators and lasso.
With telasso, you get everything you expect from treatment effects and from lasso. You can estimate the average treatment effect, the average treatment effect on the treated, and the potential-outcome means. You can model continuous, binary, and count outcomes and choose between a logit or probit treatment model. And for selection of controls, you can choose between lasso or square-root lasso estimation and choose from several selection methods, such as BIC and cross-validation.
Let’s see it work
We would like to compare two types of lung transplants: bilateral lung transplant (BLT) and single lung transplant (SLT). BLT is usually associated with a higher death rate in the short term after the operation but with a more significant improvement in the quality of life than SLT. As a result, for patients who need to decide between these two treatment options, knowing the effect of BLT (versus SLT) on life quality is essential. Therefore, we want to estimate the effect of the treatment transtype on the outcome fev1p. This outcome represents the percentage of forced expiratory volume in one second (FEV1) that the patient has relative to a healthy person.
Our data include 29 variables recording characteristics of the patients and donors. We use these variables and the interactions between them as controls in our model. It would be tedious to type these variable names one by one to distinguish between continuous and categorical variables. vl is a suite of commands that simplifies this process.
The following code creates the control variable list and stores it in the global macro $allvars.
. quietly vl set . vl create cvars = vlcontinuous - (fev1p) note: $cvars initialized with 12 variables. . vl create fvars = vlcategorical - (transtype) note: $fvars initialized with 17 variables. . vl sub allvars = c.cvars i.fvars c.cvars#i.fvars
Now we are ready to use telasso to estimate the average treatment effects. We assume a linear outcome model and a logit treatment model, the defaults. We type
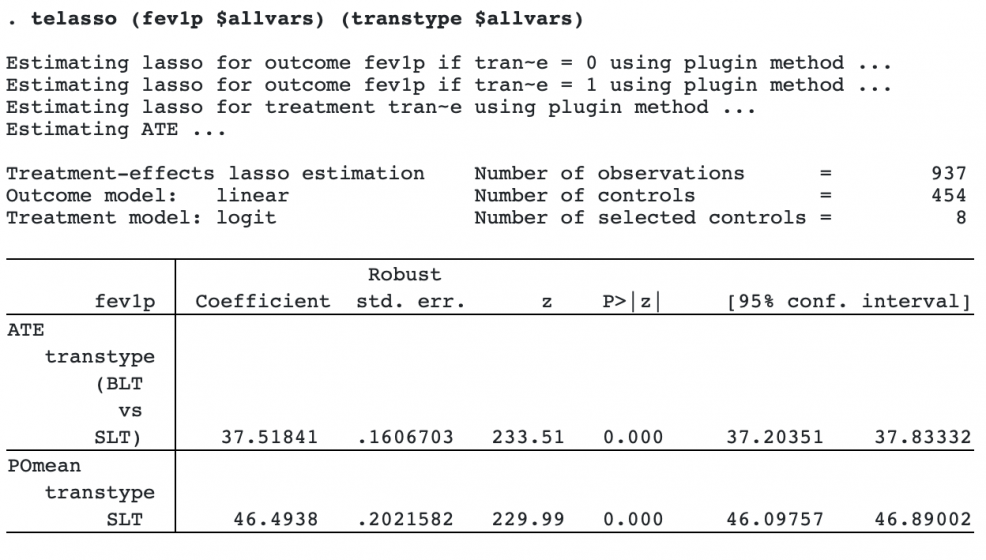
If all the patients were to choose a BLT, the FEV1% is expected to be 38 percentage points higher than the average of 46% expected if all patients were to choose an SLT. Among the 454 control variables, telasso selects only 8 of them.
It is common to estimate the average treatment effect to determine the effect on those who actually received the treatment. To estimate this value, we add the atet option.
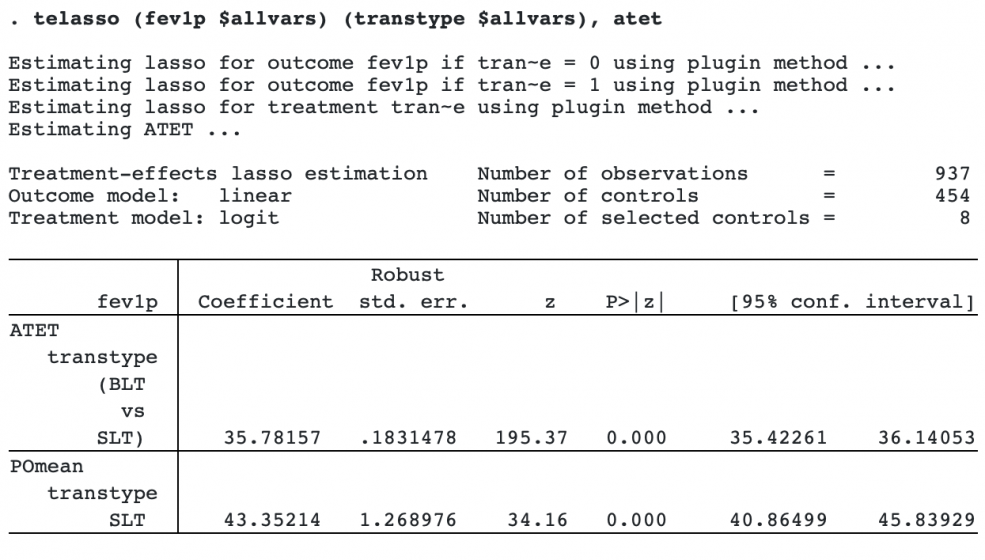
For the patients who have a BLT, we expect the average FEV1% to be 36 percentage points higher than if all of them choose an SLT.
The estimates that we obtained above relied on a key assumption of lasso, the sparsity assumption, which requires that only a small number of the potential covariates are in the “true” model. We can use a double machine learning technique to allow for more covariates in the true model. To do this, we add the xfold(5) option to split the sample into five groups and perform cross-fitting and add the resample(3) option to repeat the cross-fitting procedure with three samples.
To guarantee that we can later reproduce the estimation results, we also set the random-number seed. We type
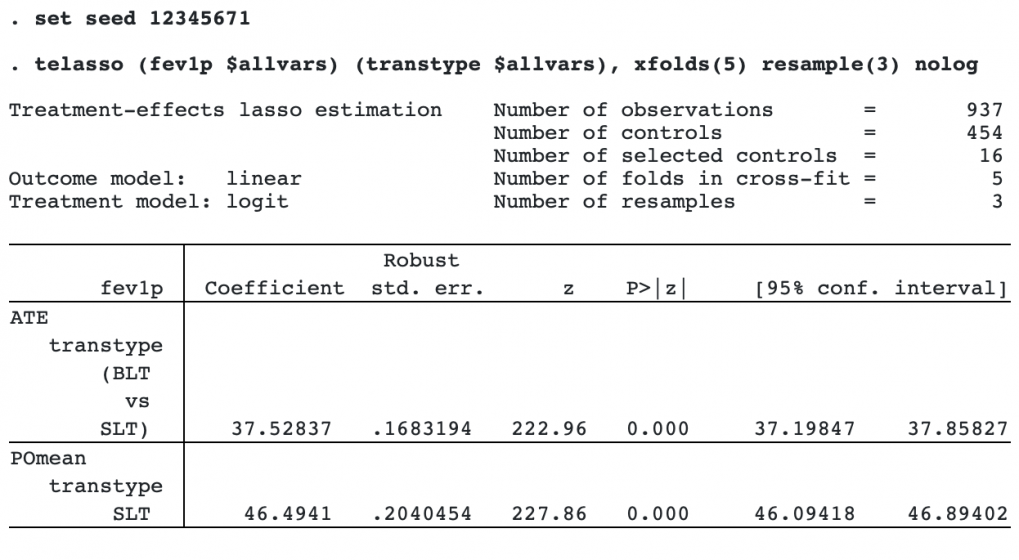
The estimated treatment effect is very similar to the one reported by the first telasso command, but the selected model included 16 controls instead of 8. The similarity of the estimates across the different specifications suggests that our first model did not suffer from a violation of the sparsity assumption.