ROBUST INFERENCE FOR LINEAR MODELS IN ACTION!
Researchers would like to study the effect of belonging to a union on the log of wages ln_wage in a panel data set of individuals. They control for whether the individual has a college degree collgrad, for length of job tenure, and for time fixed effects.
One can compare several methods of computing standard errors: robust, cluster–robust, cluster–robust HC2 with degrees-of-freedom adjustment, and two-way clustering. The second and third methods account for correlation at the industry level. The last method accounts for correlation at both the industry level and occupation level. In this example, only 12 clusters are used, which violates the assumption of asymptotic approximation that the number of clusters grows with the sample size. The sample is restricted to observations where industry code ind_code is available. The estimation results are also stored. Type:

Instead of looking at all the regression output tables, we combine them into an estimates table by using etable.
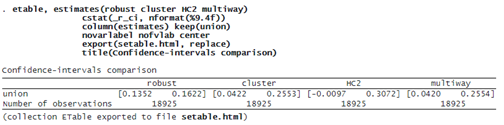
We asked etable to use the estimates we stored and to present only the CIs, cstat(_r_ci, …), for the coefficient on union, keep(union). We then export the table to the .html table you see on this page, export(setable.html, replace).
© Copyright 1996–2026 StataCorp LLC. All rights reserved.
The CIs are the narrowest with robust standard errors. They are the widest with HC2 degrees of freedom–adjusted standard errors. In the latter case, 0 is inside the CI, which suggests we should be careful when interpreting the effect of belonging to a union on wages. This is in contrast with the conclusion we would have made had we used only robust standard errors. Finally, there appears to be little difference between clustering at the industry level and clustering at both industry and occupation levels.
We can also use wild cluster bootstrap to account for a small number of clusters and an unequal number of observations per cluster. It is implemented in the new wildbootstrap command. We describe this feature in detail in Wild cluster bootstrap, but let’s also use it here for comparison.
. wildbootstrap regress ln_wage tenure union collgrad i.year, cluster(ind_code) coefficients(union) rseed(111)
wildbootstrap calls regress. So after it is done, you can still access the regress results. But, additionally, wildbootstrap constructs wild cluster bootstrap CIs for the null hypothesis that a coefficient is 0. By default, it uses all coefficients, but you may select which ones you would like to study. We focus on union. Because we are resampling at the cluster level, we specify the ind_code variable in cluster(), and we set a seed for reproducibility.
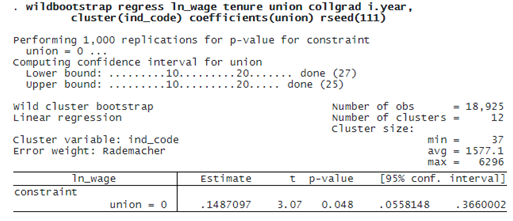
The CI reported by wildbootstrap is almost as wide as that reported when we used HC2 standard errors. Although 0 is not in the CI, it suggests that there is a wide variability in the point estimate.