
WordStat is a flexible and easy-to-use text analysis software – whether you need text mining tools for fast extraction of themes and trends, or careful and precise measurement with state-of-the-art quantitative content analysis tools. WordStat can be used by anyone who needs to quickly extract and analyse information from large amounts of documents. Provalis Research content analysis and text mining software can be used in many applications such as analysis of open-ended responses, business intelligence, content analysis of news coverage, fraud detection and more. WordStat‘s seamless integration with SimStat – our statistical data analysis tool – QDA Miner – our qualitative data analysis software – and Stata – the comprehensive statistical software from StataCorp, gives you unprecedented flexibility for analyzing text and relating its content to structured information, including numerical and categorical data.
WHAT IT IS USED FOR?
WordStat can be used by anyone who needs to quickly extract and analyze information from large amounts of documents. Our content analysis and text mining software is used for:
- Directly import text and quantitative data from social media, online survey platforms, reference management tools
- Content analysis of open-ended responses, interview or focus group transcripts
- Business intelligence and competitive web sites analysis
- Information extraction and knowledge discovery from incident reports, customer complaints
- Content analysis of news coverage or scientific literature
- Automatic tagging and classification of documents
- Fraud detection, authorship attribution, patent analysis
- Taxonomy development and validation
WORDSTAT CONTENT ANALYSIS DICTIONARIES
Many WordStat users develop their own content analysis dictionaries. Such dictionaries are usually customized to the type of data being analyzed and to the variables that need to be measured. However, having access to existing dictionaries from others authors may be useful in many ways. It allows the analyst to easily assess other dimensions and quickly get a different perspective on his text data. It also makes his results comparable to those published in other studies. Such dictionaries may also represent a great source of inspiration for developing one’s own dictionary.
WORDSTAT SOFTWARE DEVELOPMENT KIT (SDK)
The WordStat software development kit (SDK) provides a solution , allowing models developed with the WordStat desktop tool to be used in other applications written in other computer languages such as C++, Delphi, C#, VB.Net and so on.
An example of such integration would be the application of a categorization model on a company data collection system of customer feedback in order to automatically measure references to specific topics and to classify those feedbacks as either positive, negative or neutral.
With WordStat, Data Analysts can quickly extract valuable text analytics results from large collections of documents such as customer feedback, emails, open-ended responses, interview transcripts, incident reports, patents, legal documents, blogs, websites, and more. Here is a list of content analysis and text mining features of WordStat:
| IMPORT FROM MANY SOURCES
WordStat allows you to directly import content in multi-languages from many sources:
ORGANIZE YOUR DATA Several features allow you to easily organize your data in ways that make your analysis process straightforward:
QUICKY EXTRACT MEANING USING EXPLORER MODE Quickly and easily extract meaning from large amounts of text data using Explorer mode, specially made for those with little text mining experience.
Identify the most frequent words, phrases, and extract the most salient topics in your documents with the topic modeling tool. At any time, you can switch to Expert mode which gives you access to all WordStat’s features.
EXPLORE DOCUMENT CONTENT USING TEXT MINING In a few seconds, explore the content of large amounts of unstructured data and extract insightful information:
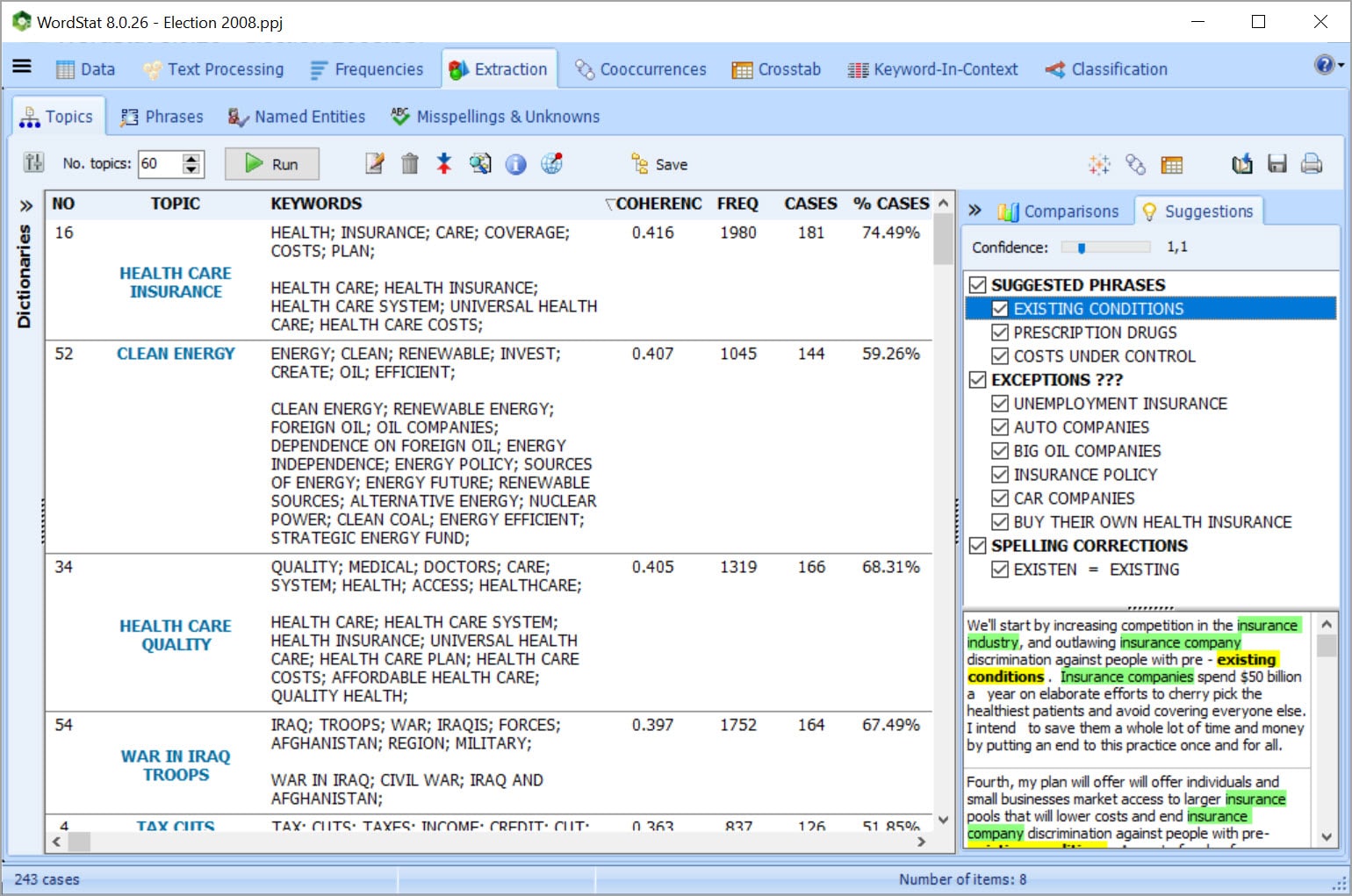
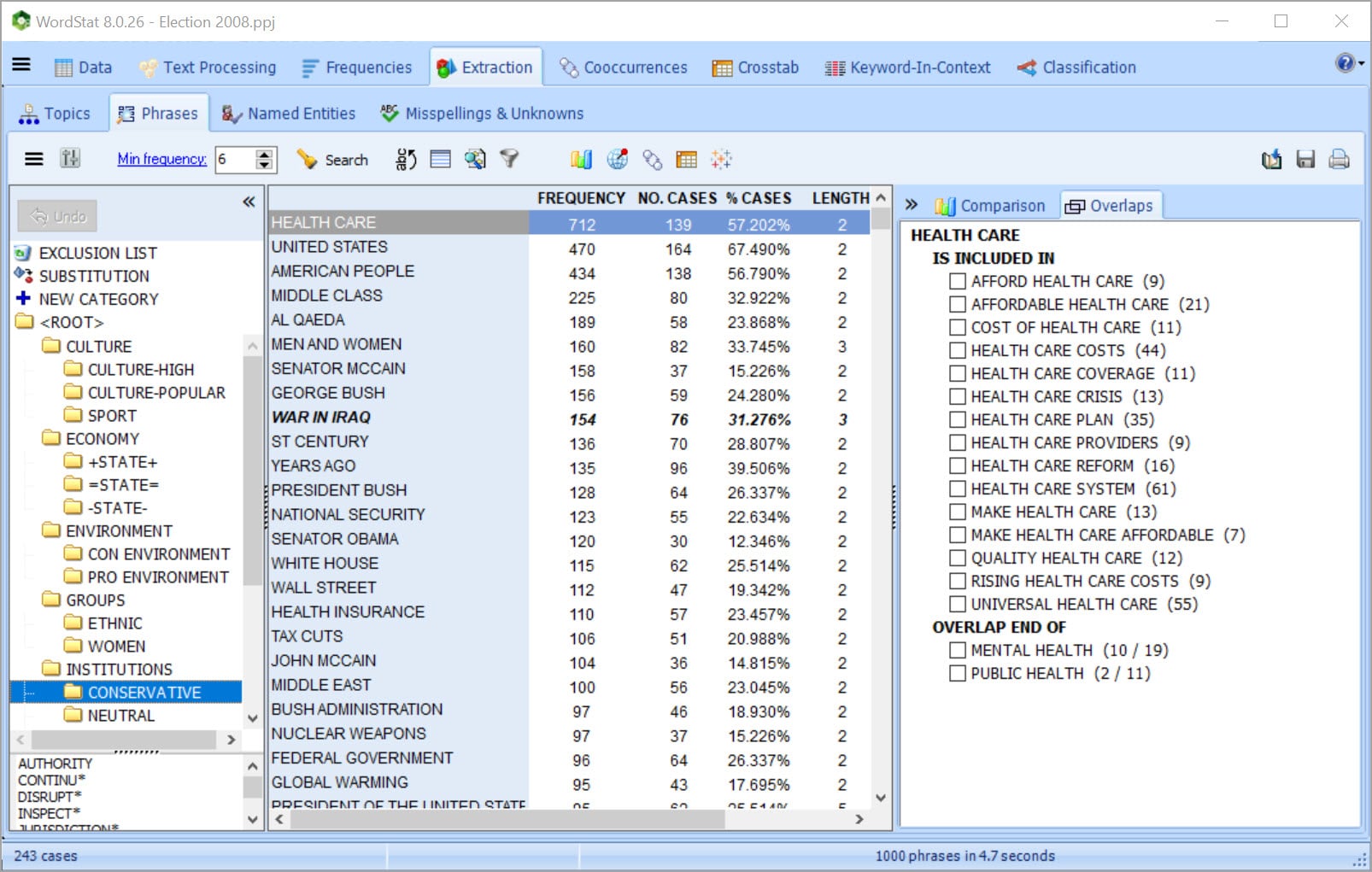
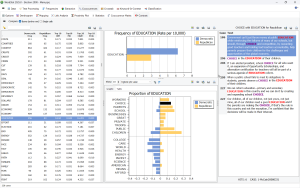
USE TOPIC MODELING TO EXTRACT THE MOST SALIENT TOPICS Get a quick overview of the most salient topics from very large text collections using state-of-the-art automatic topic extraction by applying a combination of natural language processing and statistical analysis (NNMF or factor analysis) not only on words but also on phrases and related words (including misspellings).
While in hierarchical cluster analysis, a word may only appear in one cluster, topic modeling may result in a word being associated with more than one topic, a characteristic that more realistically represents the polysemous nature of some words as well as the multiplicity of contexts of word usages.
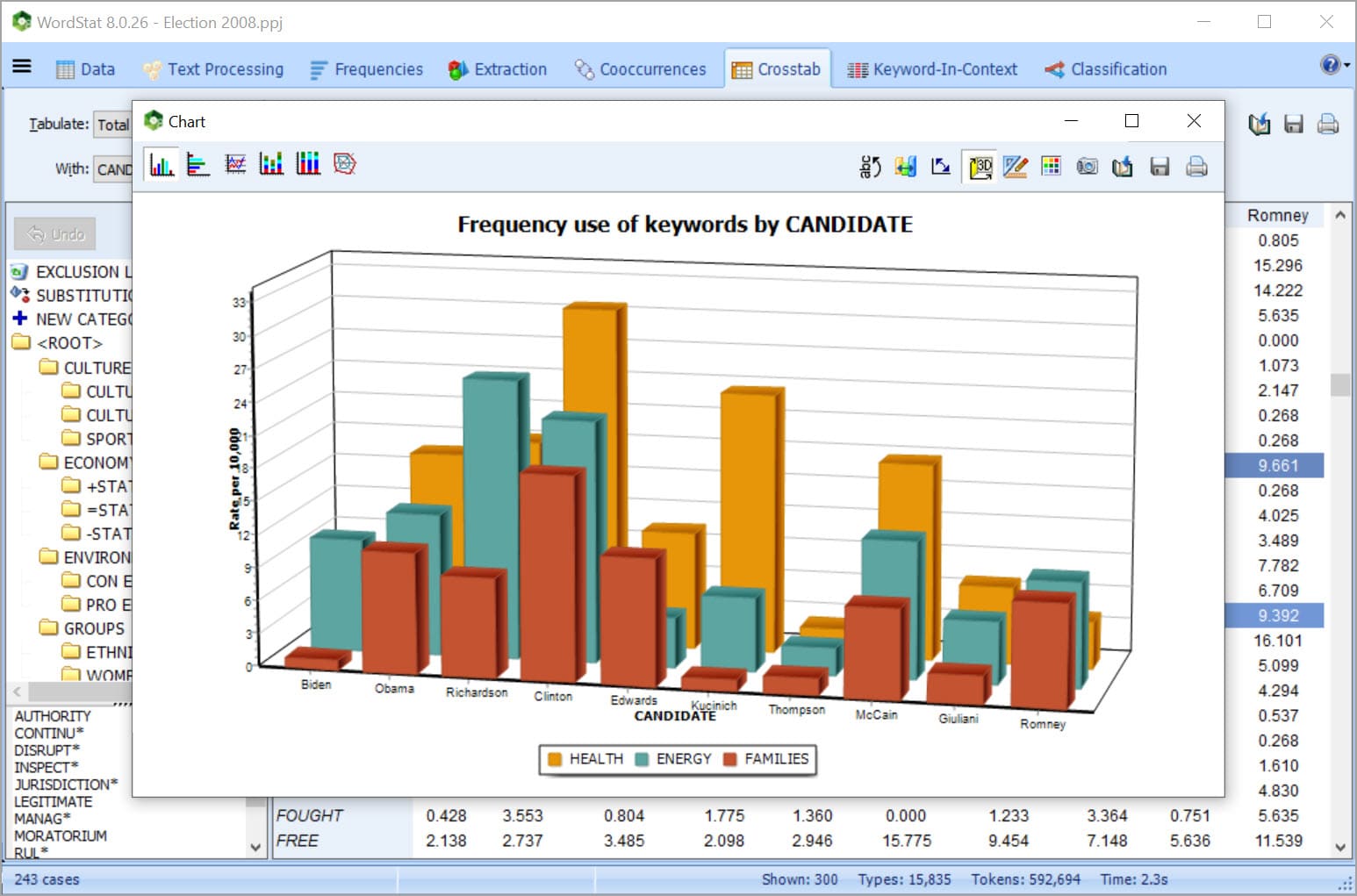
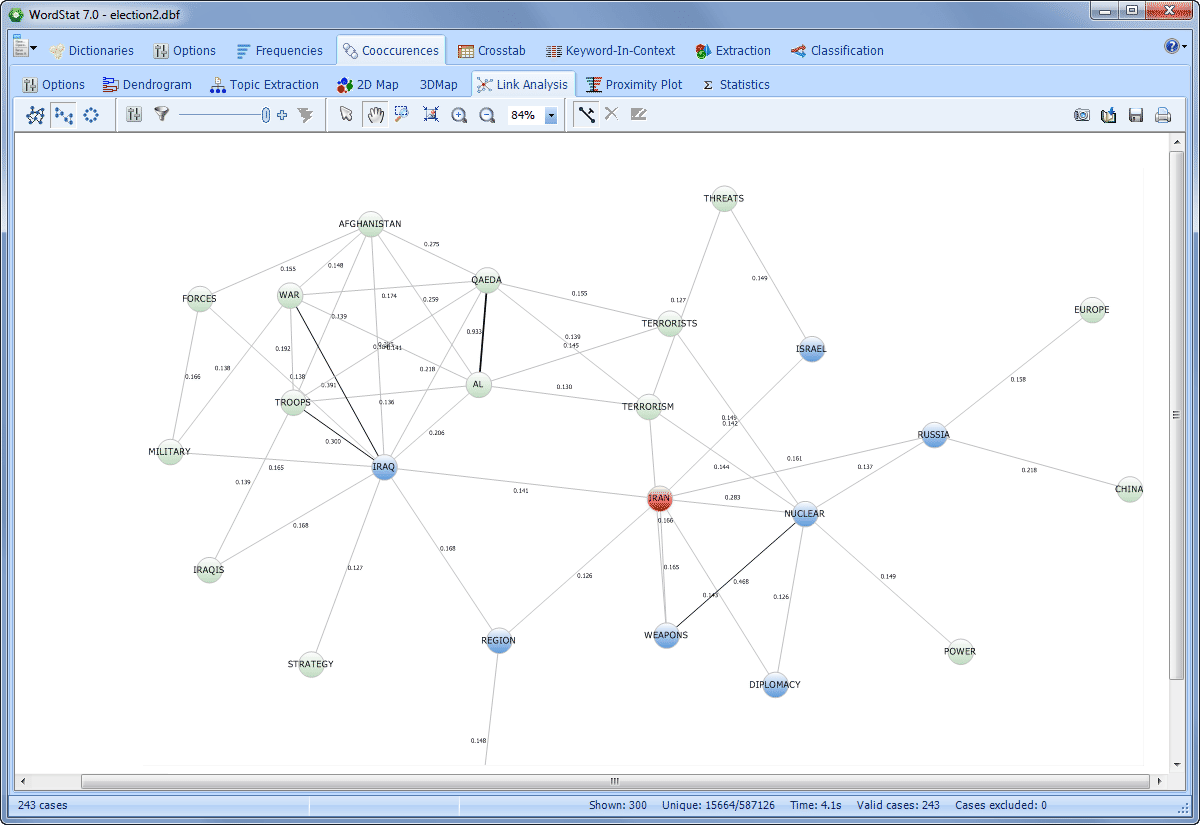
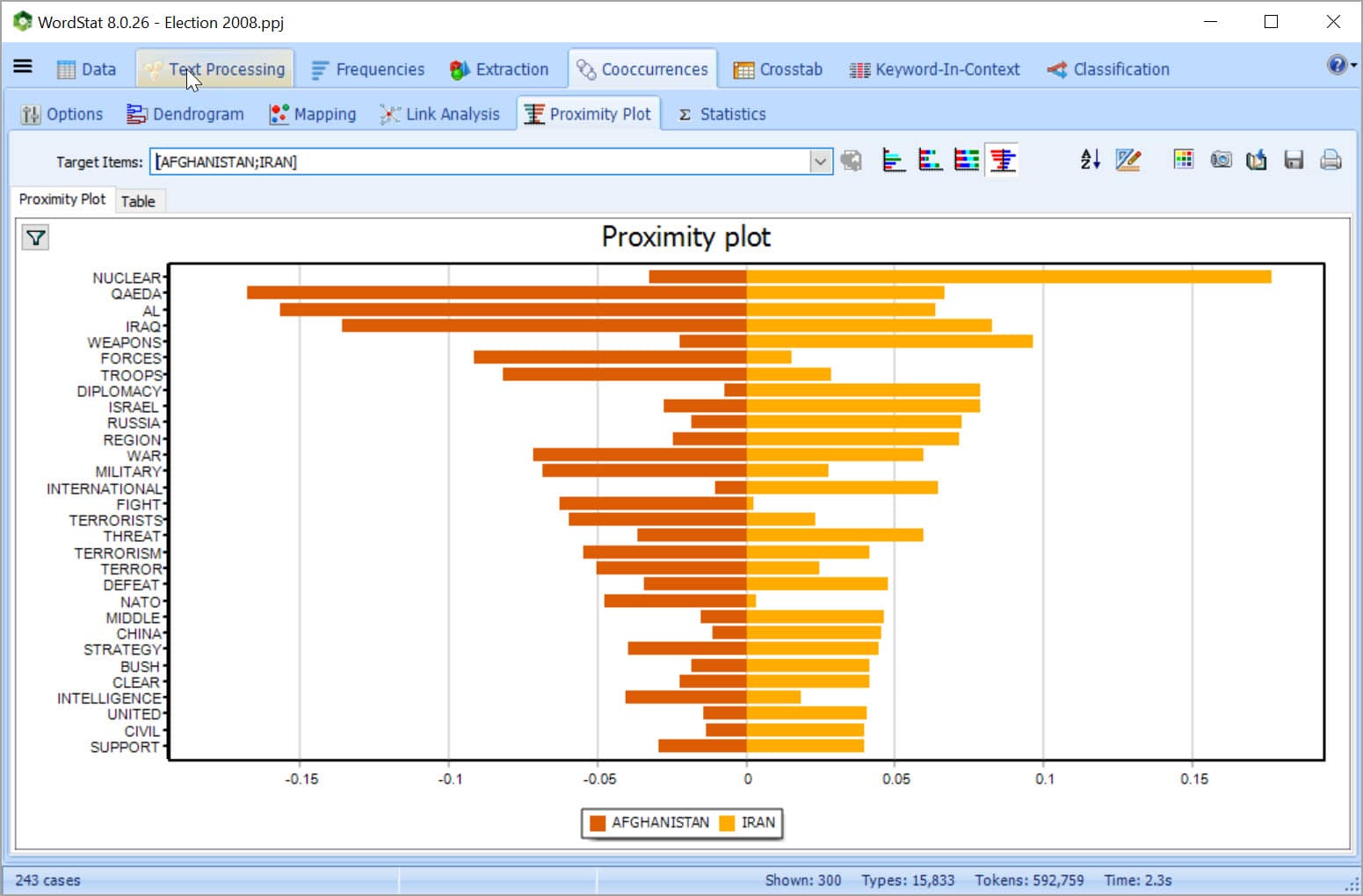
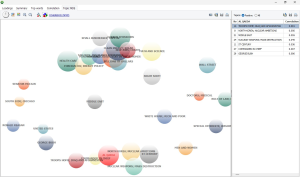
EXPLORE CONNECTIONS Explore connections among words or concepts using a network graph. Detect underlying patterns and structures of co-occurrences using three layout types: multidimensional scaling, a force-based graph, and a circular layout.
Graphs are interactive and may be used to explore relationships and to retrieve text segments associated with specific connections.
RELATE TEXT WITH STRUCTURED DATA Explore relationships between unstructured text and structured data:
|
 CATEOGORIZE YOUR TEXT DATA USING DICTIONARIES Achieve full-text analysis automation using existing dictionaries or create your own categorization model of words and phrases.
In the dictionary, one can implement Boolean (AND, OR, NOT) and proximity rules (NEAR, AFTER, BEFORE) and use Regular Expression formulas to quickly extract specific information from text data.
Dictionary moderated lemmatization and stemming are available in several languages and an automatic word substitution option allows you to substitute several words with a target keyword. A user-defined list of stop words is available in several languages to avoid nonessential frequent words such as he, she, it, etc in the analysis.
GET UNIQUE ASSISTANCE FOR DICTIONARY BUILDING Get truly unique computer assistance for taxonomy building with tools for extracting common phrases and technical terms and for quickly identifying in your text collection misspellings and related words (synonyms, antonyms, holonyms, meronyms, hypernyms, hyponyms).
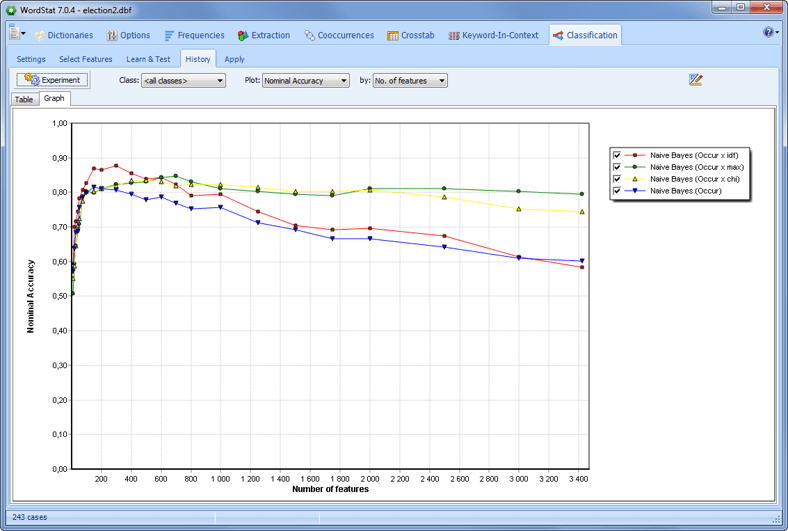
AUTOMATICALLY CLASSIFY YOUR TEXT DATA USING MACHINE LEARNING Develop and optimize automatic document classification models using Naïve Bayes and K-Nearest Neighbours. There are numerous validation methods that users can select: leave-but-one, n-fold cross-validation, split sample. An experimentation module can be used to easily compare predictive models and fine-tune classification models.
Classification models may be saved to disk and applied later in QDA Miner, in a standalone document classification utility program, a command-line program or a programming library.
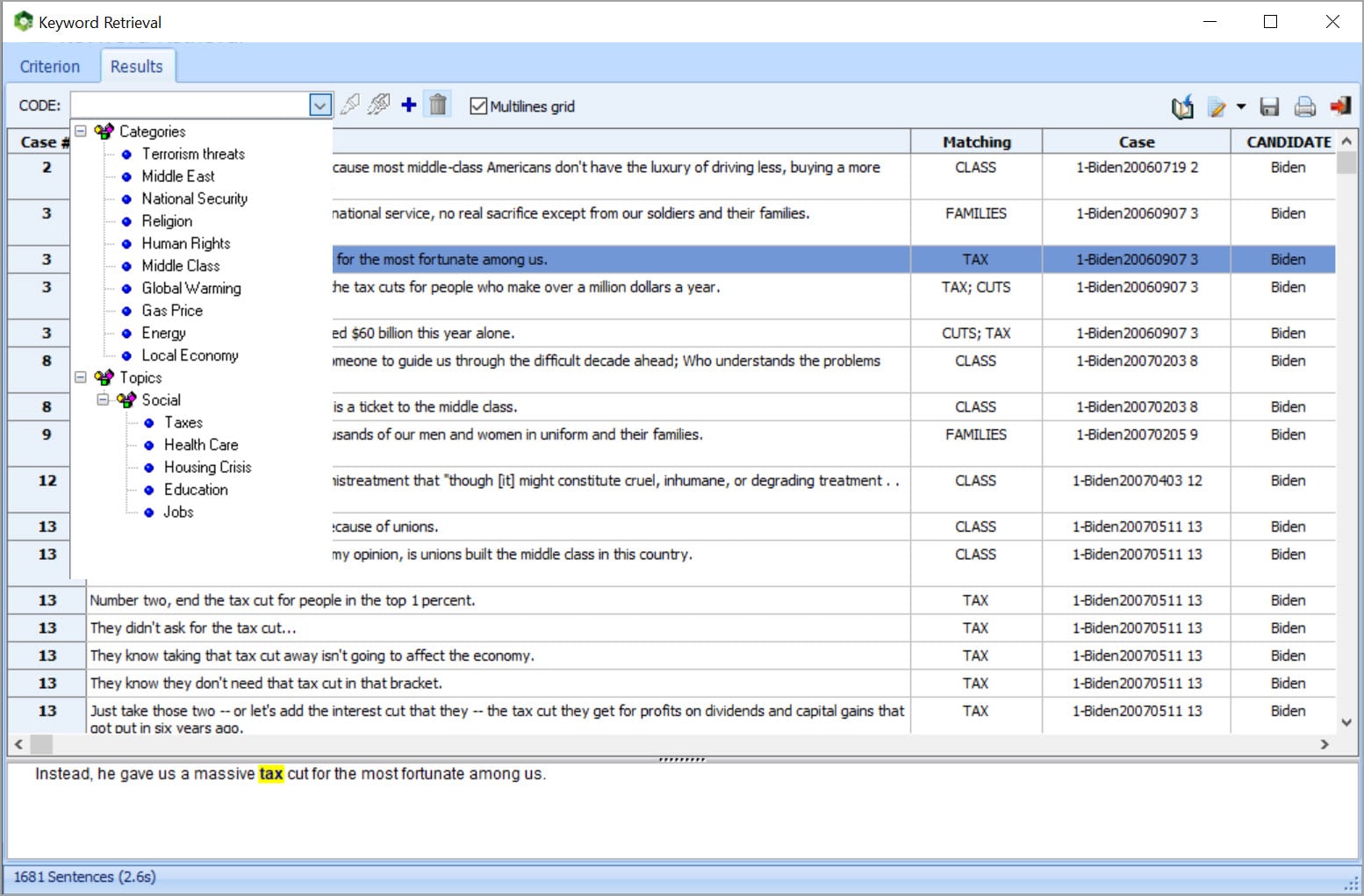
RETURN TO THE SOURCE DOCUMENT IN ONE CLICK Verify or dig deeper into your analysis by going back to the text from almost any feature, chart, or graph using Keyword Retrieval or Keyword-in-Context to retrieve sentences, paragraphs, or whole documents. This is particularly helpful when building taxonomies or for word-sense disambiguation.
The retrieved text segments can be sorted by keyword or any independent variable. You can attach QDA Miner codes to retrieved segments or export them to disk in tabular format (Excel, CSV, etc.) or as text reports (MS Word, RTF, etc.).
PERFORM QUALITATIVE CODING Combine WordStat with a state-of-the-art qualitative coding tool (QDA Miner), for more precise exploration of data or a more in-depth analysis of specific documents or extracted text segments when needed.
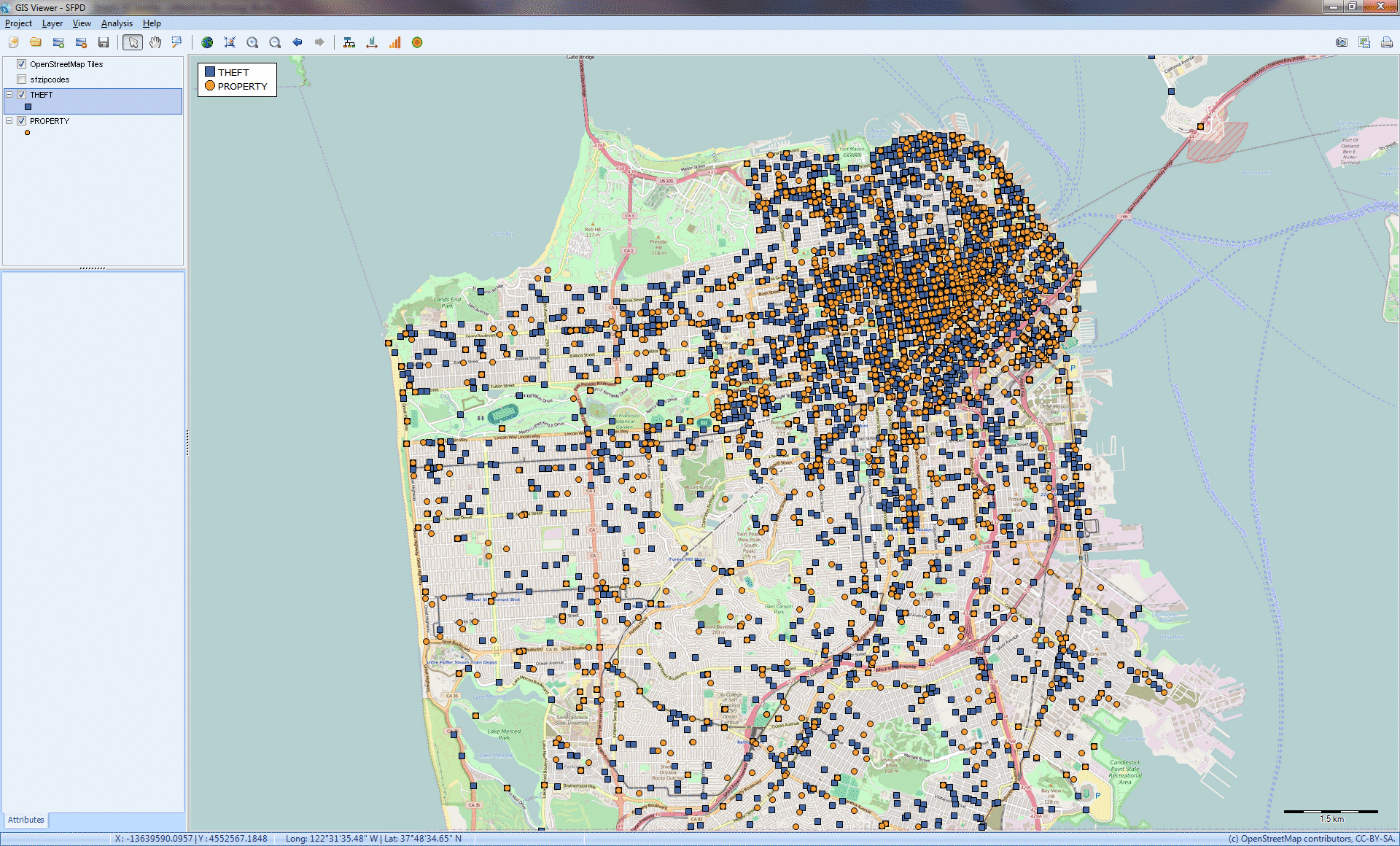
TRANSORM UNSTRUCTURED TEXT INTO INTERACTIVE MAPS (GIS MAPPING) Relate unstructured text data with geographic information and create interactive plots of data points, thematic maps, and heatmaps, along with a geocoding web service for transforming location names, postal codes and IP addresses into latitude and longitudes.
AUTOMATICALLY EXTRACT NAMENS AND MISSPELLINGS Automatically extract named entities (names, technical terms, product and company names) that can be added to the categorization dictionary using an easy drag-and-drop-operation.
Misspellings and unknown words are automatically extracted and matched with existing entries in the user dictionary and may be quickly added to the dictionary.
EXPORT RESULTS Export text analysis results to common industry file formats such as Excel, SPSS, ASCII, HTML, XML, MS Word, to popular statistical analysis tools such as SPSS and STATA and to graphs such as PNG, BMP, and JPEG.
TRANSFORM TEST USING PYTHON SCRIPTS Use Python script and its full range of open-source libraries to preprocess or transform text documents for analysis in WordStat.
|





WHAT’S NEW IN VERSION 2025
Introducing WordStat 2025: AI-Enhanced Text Analysis
Generative AI has revolutionized text analysis, but it still faces challenges on more complex tasks. It also has limited scalability, potential biases and high cost, as well as lack of transparency. WordStat 2025 bridges the gap by seamlessly integrating generative AI with existing advanced text mining, NLP, and machine learning techniques, offering researchers complete control. Choose from leading AI engines, customize prompts, and even create your own for tailored analysis.
This release also brings major enhancements to existing features and introduces a groundbreaking tool for exploring differences in co-occurrences—delivering deeper insights with precision and ease.
A PDF documenting the new features can be downloaded by clicking here.
|
CHOICE OF SEVERAL AI ENGINES AND MODELS WordStat 2025 offers the possibility to perform text analysis and transformation using the engine of your choice among five online options (OpenAI, Gemini, Claude. Mistral, or Perplexity) and one offline option (Ollama). Users may also choose the model that provides them the performance they need at a price that fit their budget.
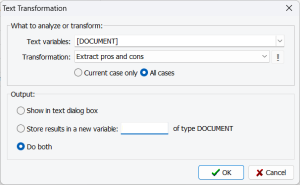
NEW AI-POWERED TEXT ANALYSIS AND TRANSFORMATION ROUTINES We evaluated multiple AI-driven features and integrated those that demonstrated strong performance, in some cases surpassing existing WordStat capabilities—though with trade-offs in processing speed and cost. Among the most effective implementations are sentiment analysis, pros and cons extraction, spelling correction, and automatic translation, all of which deliver highly accurate results across most AI engines. Additionally, we introduced AI-assisted readability scoring, lemmatization, segmentation of Asian languages (Chinese, Japanese, Thai, etc.), as well as grouping of Vietnamese monosyllabic tokens.
AI-ENHANCED NAMING OF TOPIC MODELS While generative AI engines are still unable to perform topic modeling on large datasets, they excel as providing relevant names to the extracted topics. While WordStat did already provide topic names, it is now possible to obtain more descriptive AI-generated names.
AI GENERATED GROUPING OF TOPICS A new AI script can be used to automatically identify grouping categories for extracted topics and then add the theme descriptor to the topic table. Saving the topics in a dictionary ends up with a hierarchical dictionary with themes at the first level, topics at the second level, and word and phrases at the third level.
AI SYNTACTIC CLASSIFICATION OF PHRASES WordStat 2025 enhances its phrase extraction routine by offering the possibility to use AI to classify extracted phrases based on their syntactic category. Once phrases are extracted, AI can be used to assign them to grammatical classes such as noun phrases, verb phrases, adjective phrases, prepositional phrases, etc. This categorization offers a more structured analysis, allowing users to focus on specific themes or topics, behaviors, processes, emotions, or other elements associated with different syntactic phrase types.
AI-BASED NAMED ENTITY CLASSIFICATION Traditional named entity recognition struggles with ambiguous terms and context-dependent meanings. WordStat 2025 introduces AI-powered entity classification which takes into account the surrounding context to accurately categorize names, organizations, locations, and more—reducing errors and improving precision in entity classification.
CUSTOM AI SCRIPTS FOR POST-PROCESSING AND ANALYSIS WordStat 2025 allows users to create custom scripts for post-processing table outputs, for applying text analysis or data transformation on the text dataset. |
With this flexibility, you can tailor the software to meet your specific needs by automating repetitive tasks, applying custom preprocessing operations, or integrating external routines.
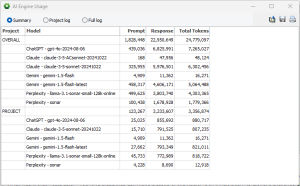
MONITOR AI TOKEN CONSUMPTION Token consumption across engines, models, and projects can be easily monitored, providing better control over costs. Users can also obtain an estimated token count for prompts before execution, helping to prevent costly data transformations and analyses. This allows for better decision-making when selecting models, ensuring cost-effective usage.
EXPLORE CO-OCCURRENCE COMPARISON ACROSS GROUPS WordStat 2025 introduces a powerful feature for comparing co-occurrence patterns between groups, revealing subtle differences that traditional frequency-based methods may miss. While frequency analysis highlights general trends, it overlooks how words or topics may be associated in unique ways within each group. This tool helps identify contextual variations, such as how the same term may be linked to different concepts, concerns, issues, or proposed solutions. Comparisons can be made within subgroups of the current dataset or by using previously saved co-occurrence matrices from different datasets. We are confident that this tool will unlock numerous new possibilities and potentially generate the wealth of interesting discoveries for researchers and data analysts.
EXPLORE TOPIC RELATION WITH INTERACTIVE MDS PLOT WordStat 2025 introduces an interactive MDS plot that visualizes topic correlations in a two-dimensional map. Topics are represented as points or bubbles of different sizes representing frequencies or measured coherence, with distance indicating correlation strength—closely placed topics are highly correlated, while those farther apart show weaker or negative correlations. Clicking on a topic reveals a correlation table, allowing you to explore related topics in descending order of correlation strength. This feature offers a clear, dynamic way to understand and explore topic relationships.
NEW TOPIC DIVERSITY MEASURE Topic modeling results include a new measure for assessing topic diversity. This measure helps evaluate how varied the topics are within a model, providing a clearer understanding of the range and uniqueness of topics discovered.
IMPROVED DICTIONARY ASSISTANCE PANEL The Dictionary Assistance panel used to assess interactions between dictionary entries and evaluate the impact of wildcards now includes the ability to display the frequency of words matching the selected pattern in the current dataset. Additionally, panel entries can be filtered to show only items that are present in the dataset, streamlining the analysis process. |
Per consultare i termini e le condizioni d’uso della casa produttrice del Software Provalis Research, cliccare qui
End User license agreement
1.Object
Throughout the term of this Agreement and subject to its terms and conditions, Provalis Research Corp. (hereinafter “Provalis”) authorises CLIENT to use the Provalis proprietary computer program(s) identified in the relevant invoice, (hereinafter the “Software”) in consideration for the price mentioned in the relevant invoice.
2. USE
The CLIENT will use the Software for the purposes described in Section 3.1 and will comply with the conditions described herein.
3. Licence
3.1 Licence
Subject to the terms and conditions expressed herein, Provalis hereby grants CLIENT a non-exclusive licence to use the Software, for the duration specified in the relevant invoice, in machine readable form, on up to two computers, provided that there is no chance it will be used simultaneously on more than one computer.
3.2 Software Ownership
CLIENT acknowledges that no right, title or interest, other than the right to use the Software in the manner described herein, is transferred by the present Agreement. CLIENT agrees that Provalis is and shall remain owner of all copyright, trade secret, patent, trademark and other proprietary rights in and to the Software. The technical procedures, processes, systems, methods of operation, and concepts which are embodied within the Software are trade secret information of Provalis and/or its licensor(s). This licence is not a sale of a copy of the Software and does not render CLIENT the owner of a copy of the Software.
3.3 Copying
CLIENT may not make copies of the Software, except those copies which are needed for backup purposes. CLIENT will advise its employees who are granted access to the Software of the restrictions upon duplication, reverse engineering, disclosure and use contained in this Agreement. CLIENT will be liable for any unauthorised copying, reverse engineering, disclosure and/or use by its employees or agents.
3.4 Prohibitions
The CLIENT shall not, without the express prior written consent of Provalis:
a) use the Software under any name other than that of CLIENT;
b) lease, rent, sell, pledge, convey, assign, sublicense, loan, distribute or otherwise transfer to any third party the Software, in whole or in part, or any copy thereof, or any derived works or adaptations based thereupon;
c) subject to what is allowed in Section 3.1, use the Software licensed under an Academic license in any manner to provide computer services to third parties;
d) transfer to any third party any of CLIENT’s rights under this Agreement or otherwise encumber or offer the Software as security; or
e) modify, translate, convert to another programming language, or prepare derived works or adaptations from the Software.
CLIENT shall not modify, dismantle, or decompile or allow anyone to modify, dismantle, or decompile the Software or any portion thereof in any possible way. CLIENT further agrees that it shall not use the Software to assist in the development or design of a computer program that is intended to provide substantially similar functionality as the Software. The Software shall not be used to develop, nor shall CLIENT market, any conversion utility or aid specific to the Software enabling or facilitating users to convert from the Software or a database created by using the software to an alternative software or alternative database not marketed by Provalis.
4. Obligations of Client
4.1 Responsibility
4.1.1 Security
CLIENT shall be responsible for ensuring the security of the Software, as to physical and electronic intrusions. In particular, in order to protect the trade secrets included in the Software, CLIENT shall protect the areas of the CLIENT’s premises and computing infrastructure where the Software is installed or stored, with adequate security measures so as to prevent unauthorised persons from gaining access and restrict access to those persons having a need to access the Software.
4.1.2 Damage to Software
CLIENT shall be responsible for any damage to the Software.
4.1.3 Result
CLIENT acknowledges that Provalis shall have no control over the conditions under which CLIENT and its employees use the Software and CLIENT therefore agrees to assume the responsibility of the results obtained from the Software provided to CLIENT by Provalis.
5. Notices
Any notice, request, instruction, legal proceedings or other instrument to be given, served, or provided under this Agreement by either party shall be deemed given and received when in writing and delivered personally or five (5) days after being sent by certified or registered mail (postage prepaid) properly addressed to the intended recipient of Provalis or CLIENT, at the address of each as indicated in the header of this Agreement, provided that either party may change such address, only by written notice to the other party.
6. Express Rights
6.1 Intellectual Property
Provalis warrants that it has the right to grant this licence to use the Software as contemplated hereunder. Subject to the limitations of Section 10, Provalis will indemnify CLIENT and hold CLIENT harmless against any damages awarded in a final judgement against CLIENT, arising out of any claim, by a third party, that the Software infringes or violates any copyright, trademark or trade secret rights of such third party, in Canada or the United States, provided that:
a) CLIENT notifies Provalis promptly in writing of any notice of any such claim;
b) CLIENT cooperates with Provalis in all reasonable respects in connection with the investigation and defence of any such claim;
c) CLIENT has not prejudiced Provalis position’s in any way, by, without limiting the generality of the foregoing, its admissions and/or declarations; and
d) Provalis has and retains at all time sole control of the defence of any action on any such claim and all negotiations for its settlement or compromise.
Should the Software become, or in Provalis’ opinion be likely to become, the subject of a claim of copyright, patent or trademark infringement or trade secret misappropriation, in Canada or the United States, CLIENT will permit Provalis, at Provalis’ option and expense, either to:
i) procure for CLIENT the right to continue using the Software;
ii) replace or modify the same so that it becomes non-infringing; or
iii) terminate this licence, return to the CLIENT the price of the license minus linear (straight line) depreciation calculated monthly over:
– three (3) years from the date of the purchase of the Software, in the case of perpetual licenses,
– twelve (12) months from the date of the purchase of the Software, in the case of annual licenses, and accept the return of the Software.
Notwithstanding anything herein to the contrary, however, Provalis shall have no obligation or liability to CLIENT under any provision of this Sub-Section if any copyright, patent or trademark infringement or trade secret misappropriation claim is based upon:
f) the use of other than a current unaltered release of Software if the infringement would have been avoided by the use of a current unaltered release of Software;
g) the combination, operation or use of any Software with any programs, software or equipment not provided by Provalis, if the infringement would have been avoided by the combination, operation or use of Software with other programs, software or equipment;
h) the use of the Software in other than the operating environment specified for it by Provalis if the infringement would have been avoided by use in the operating environment specified by Provalis;
i) the use of or access to the Software in a manner other than that for which it was furnished by Provalis; or
j) the use of any Software which has been modified by or for CLIENT in such a way as to cause it to become infringing.
6.2 Identification
CLIENT expressly agrees to allow Provalis to disclose the existence of the Agreement and the fact that CLIENT is a client of Provalis.
7. Confidentiality
7.1 Confidential Information
CLIENT acknowledges that the Software as well as any technical information, design concepts, methods, processes, procedures, formulae, or algorithms contained therein constitute trade secrets, are given access to by Provalis to CLIENT in confidence, and contain proprietary and confidential information.
7.2 Nondisclosure
Each party shall use the same care to prevent disclosure of the confidential information of the other party to third parties as it employs to avoid disclosure, publication, or dissemination of its own information of a similar nature, but in no event less than a reasonable standard of care.
– CLIENT further agrees that it will not, under any circumstances except as expressly authorised hereby, distribute or disseminate any information contained in or disclosed by the Software, including but not limited to any technical information, design concepts, methods, processes, procedures, formulae, or algorithms, to any person except to those of its employees and/or other users with a need-to-know and whose access is necessary for CLIENT’s use as set forth above. This does not prevent the user from communicating to third parties the results of processing data with the Software.
CLIENT will take appropriate action with such employees and/or other users, to inform them of the trade secret, proprietary and confidential nature of the Software, to obtain their compliance with the terms of this section and to have them accept in writing the confidentiality obligations contained herein or similar confidentiality obligations, of similar stringency. In the event that CLIENT, or any of its present or former employees and/or other users breaches the confidentiality obligations of this Agreement, CLIENT shall be jointly and severally liable to Provalis for any loss incurred by Provalis resulting directly or indirectly from such breach.
7.3 Relief
The Parties acknowledge and agree that the Software, as well as all other information in whatever medium disclosed to CLIENT hereunder are unique and commercially valuable and that any breach by a party of the terms of this Agreement with respect to protection against disclosure or distribution of such information would result in an irreparable and continuing injury to the other party, for which money damages would be inadequate. In the event of such a breach or anticipated breach by one party, the other party shall be entitled to immediate injunctive relief and to specifically enforce the terms of this Agreement, in addition to any other remedy to which such other party may be entitled at law or in equity.
8. Limited Warranty
During a period of ninety (90) days from the execution of this license, Provalis will make reasonable efforts to correct any material failure of the Software to so conform or perform substantially in accordance with its documentation, provided that: a) CLIENT promptly gives Provalis detailed written notice, in the form required by Provalis, of any such claimed failure to so conform or perform; b) Provalis is able, using reasonable means, to reproduce and identify the error; c) such failure to so conform or perform is not, in Provalis’ reasonable opinion, a result of any modification of or damage to the Software or its operating environment or of CLIENT’s failure to operate or access to the Software through the proper hardware and software environment; d) such failure to so conform or perform is not, in Provalis’ reasonable opinion, a result of the interaction of the Software with other software or hardware not provided, installed or configured by Provalis; and e) such failure to so conform or perform is not, in Provalis’ reasonable opinion, a result of the Software having been subjected to negligence, unauthorised access or use, or computer or electrical malfunctions.
In the event that Provalis shall fail or be unable for any reason to correct any failure of the Software to substantially conform to or perform substantially in accordance with its documentation, CLIENT may terminate this licence and cease using the Software and benefit from its use, and shall be reimbursed for the price of the license minus linear (straight line) depreciation calculated monthly over:
– three (3) years from the date of the purchase of the Software, in the case of perpetual licenses,
– six (6) months from the date of the purchase of the Software, in the case of annual licenses,
Such remedy shall be the CLIENT’s sole remedy.
9. Disclaimer of Warranties
EXCEPT AS EXPRESSLY PROVIDED IN SECTION 8 ABOVE, ANY WARRANTY, EXPRESS OR IMPLIED, OFFERED BY THE LAW OR USAGE OF TRADE, INCLUDING WITHOUT LIMITING THE FOREGOING, ANY WARRANTIES OF QUALITY, ABSENCE OF LATENT DEFECTS, ACCURACY, PERFORMANCE, SUITABILITY OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE IS HEREBY EXCLUDED. EXCEPT AS EXPRESSLY PROVIDED IN SECTION 8 ABOVE, THE ENTIRE RISK IN CONNECTION WITH THE QUALITY AND THE OPERATION OF THE SOFTWARE IS ASSUMED BY THE CUSTOMER.
IN ADDITION, EXCEPT AS EXPRESSLY PROVIDED IN SECTION 8 ABOVE, PROVALIS DOES NOT WARRANT AND ASSUMES NO RESPONSIBILITY FOR THE TIMELINESS, LEGALITY, ACCURACY, RELIABILITY, COMPLETENESS OR UTILITY OF A DECLARATION, OF A NOTICE, OF A SERVICE OR ANY OTHER INFORMATION BASED ON THE RESULTS OF THE USE OF THE SOFTWARE.
10. Limitation of Liability
IN NO EVENT WILL PROVALIS BE LIABLE TO CLIENT OR ANY OTHER PERSON FOR ANY LOST PROFITS, LOST SAVINGS, LOST DATA, OR OTHER INDIRECT,SPECIAL, CONSEQUENTIAL OR INCIDENTAL DAMAGES ARISING OUT OF OR RELATING TO THIS AGREEMENT OR ANY INFORMATION, PRODUCT OR SERVICE FURNISHED OR TO BE FURNISHED BY PROVALIS UNDER THIS AGREEMENT OR THE USE THEREOF, EVEN IF PROVALIS HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH LOSS OR DAMAGE. IT IS SPECIFICALLY UNDERSTOOD BETWEEN THE PARTIES THAT PROVALIS SHALL HAVE NO LIABILITY WHATSOEVER CONCERNING DAMAGES ARISING OUT OF OR RELATING TO THE USE OF THE SOFTWARE. IT IS FURTHER UNDERSTOOD THAT PROVALIS SHALL ALSO HAVE NO LIABILITY WHATSOEVER CONCERNING DAMAGES ARISING OUT OF OR RELATING TO UNAUTHORISED ACCESS, ALTERATION OR DESTRUCTION, BY ANY THIRD PARTY, OF A DATABASE, THE CLIENT’S COMPUTER SYSTEM OR THE CLIENT’S FILES OR DOCUMENTS.
THE AGGREGATE LIABILITY OF PROVALIS UPON ANY CLAIMS HOWSOEVER ARISING OUT OF OR RELATING TO THIS AGREEMENT OR ANY INFORMATION, DATA, PRODUCTS OR SERVICES PROCESSED, FURNISHED OR TO BE FURNISHED BY PROVALIS UNDER THIS AGREEMENT WILL IN ANY EVENT BE ABSOLUTELY LIMITED TO THE AMOUNT PAID TO PROVALIS BY CLIENT UNDER THIS AGREEMENT FOR THIS LICENCE TO USE THE SOFTWARE.
11. Fees and Payments
CLIENT shall pay to Provalis the price set in the relevant invoice for the use of the Software, within thirty (30) days after the reception of an invoice from Provalis. Late payment may carry interest at a rate of 1% per month and 12% per year, at Provalis’ discretion. Provalis shall have and retain the right to disable CLIENT’s license in case CLIENT has not paid such amount after ninety (90) days without a valid reason.
12. Term and Termination
12.1 Term
This Agreement shall be effective commencing on the Effective Date and represents a licence to use the Software installed by Provalis, subject to the conditions described herein, for the duration specified in the relevant invoice.
12.2 Termination for Breach
Either party may terminate this Agreement upon written notice to the other party if the other party materially breaches the terms of this Agreement and such default continues uncorrected for a period of ten (10) days after notice in writing thereof to such other party. The fact that one of the parties is adjudged bankrupt; makes a proposal for the benefit of its creditors; has a receiver appointed; files a petition of bankruptcy; initiates reorganisation proceedings; causes or permits to occur any similar event under the laws of its domicile; or ceases to conduct its operations in normal course of business; or is wound up will be interpreted as a default under the terms of the present Agreement.
12.4 Effect of Termination
Upon termination of this Agreement, CLIENT will, within fifteen (15) days: a) return all whole or partial copies of the Software to Provalis; b) destroy any copy of the Software, any relevant documentation or results and certify to Provalis, in writing, that all copies not returned to Provalis have been destroyed. Upon termination, all licences granted pursuant to this Agreement and any maintenance and support agreement executed by both parties will also CLIENT shall pay immediately any and all sums then owing to Provalis hereunder together with interests, if any, accrued on said sums.
12.5 Non-Solicitation
CLIENT undertakes, during the term of this agreement and for a period of twelve (12) months after the termination of this Agreement, not to employ or attempt to employ an employee of Provalis. Should CLIENT be in default with respect to the aforementioned obligation, and should CLIENT not cure this default within three (3) days of the reception of a written notice by Provalis, CLIENT shall pay to Provalis, as anticipated damages and not as a penalty, a sum equivalent to the employee’s total remuneration, including benefits, during the six (6) months preceding its employment by CLIENT.
12.6 Survival
Sub-Sections 3.2, 3.3, 3.4, 6.1 and Sections 7, 9, 10, 12 and 13 will survive the termination of this Agreement.
13. Final Provisions
13.1 Entire Agreement
This Agreement sets forth the entire agreement and understanding between Provalis and CLIENT regarding the subject matter hereof and supersedes any prior representations, advertisements, statements, proposals, negotiations, discussions, understandings, or agreements regarding the same subject matter.
13.2 Non-Waiver
The failure by either party at any time to enforce any of the provisions of this Agreement or any right or remedy available hereunder or at law or in equity, or to exercise any option herein provided, shall not constitute a waiver of such provision, right, remedy or option or in any way affect the validity of this Agreement. The waiver of any default by either party shall not be deemed a continuing waiver, but shall apply solely to the instance to which such waiver is directed.
13.3 No Partnership or Joint Venture
It is expressly understood that this Agreement does not constitute and shall not be construed as constituting a partnership or joint venture between Provalis and CLIENT, and that both parties shall remain independent of one another. Neither party shall have the necessary legal authority to bind the other in its absence with regards to any agreement or contract.
13.4 Language
This Agreement is written in the English language, at the request of the parties. / Cette entente est rédigée en langue anglaise, à la demande des parties.
13.5 Severability
Every provision of this Agreement shall be construed, to the extent possible, so as to be valid and enforceable. If any provision of this Agreement so construed is held by a court of competent jurisdiction to be invalid, illegal or otherwise unenforceable, such provision shall be deemed severed from this Agreement, and all other provisions shall remain in full force and effect.
13.6 Choice of Law and Forum
This Agreement shall in all respects be governed by and interpreted, construed and enforced in accordance with the laws applicable within the Province of Quebec, Canada. Any action between Provalis and CLIENT will be venued in a competent court situated within the Judicial District of Montréal, in the Province of Quebec, Canada, and CLIENT irrevocably submits itself to the personal jurisdiction of such courts for such purpose.
13.7 Force Majeure
Each party shall not be in default or otherwise liable for any delay in or failure of its performance as per this Agreement should the cause of such default be beyond its control or due to a case of force majeure. Are deemed to be force majeure any unpredictable and irresistible event and any foreign cause which presents the same characteristics, notably, without limiting the foregoing, the causes beyond Provalis’ control, fire, electrical failures, failures of a telecommunication network or part thereof, floods and other acts of God, accidents, labour disputes, extra-ordinary supplying difficulties, civil unrest, orders, regulations, laws and other governmental interventions, riots, civil or military interventions and act of war (declared or not).
13.8 Assignment and Binding Effect
Provalis may assign, delegate and/or otherwise transfer this Agreement or its rights and obligations hereunder to any person or entity. CLIENT may not assign, delegate or otherwise transfer this Agreement or any of its rights or obligations hereunder without the prior written consent of Provalis. This Agreement shall be binding upon and inure to the benefit of the parties and their respective successors and permitted assigns.
Copyright © 2004-2024 Provalis Research Corp. All rights reserved. No part of this publication may be reproduced or distributed without the prior written permission of Provalis Research Corp., 2997 Cedar Avenue, Montreal, QC, H3Y 1Y8, CANADA.
CARATTERISTICHE DI SISTEMA
WordStat richiede risorse minime, funziona con appena 256 MB di RAM e 40 MB di spazio su disco. WordStat richiede:
- Windows XP, 2000, Vista, Windows 7, 8 and 10: 1GB RAM (consigliati 2GB).
- Windows 11: minimo 4GB RAM (consigliati 8GB) e 64GB di spazio su disco.
WordStat viene eseguito su Mac OS utilizzando una soluzione di macchina virtuale o Boot Camp, e su computer Linux utilizzando CrossOver o Wine. Clicca qui per ulteriori informazioni sulle modalità di esecuzione di WordStat su un computer Mac OS.
DOCUMENTAZIONE UTENTE
Il manuale Wordstat 2025 è stato integrato con il menu Help online del software. Il manuale di Wordstat 9 invece può essere scaricato qui.
TUTORIAL PROVALIS RESEARCH ONLINE
Per tutti coloro che desiderano approfondire l’utilizzo del software attraverso una serie di brevi video Tutorial on-line.
FROM BIG DATA TEXT INTO INSIGHTS
Provalis Research software is used in a wide range of application domains such as media analysis, market research, survey analysis, incident reports, and competitive intelligence. It helps researchers to ensure healthier populations, improve business performance, or raise safety standards. It supports agencies, businesses, and academics in providing better responses to the countless questions and issues impacting citizens, customers, and communities worldwide. Find out how Provalis Research tools help in transforming text data into valuable insights.
 SURVEY ANALYSIS SURVEY ANALYSIS
See how one can code answers to open-ended questions more quickly and more accurately. |
 BRAND IMAGE ANALYSIS BRAND IMAGE ANALYSIS
Find how commercial brands are perceived by customers. |
 SENTIMENT ANALYSIS SENTIMENT ANALYSIS
Measure emotions of customers, journalists, bloggers, etc. |
 SCIENTOMETRICS AND BIBLIOMETRICS SCIENTOMETRICS AND BIBLIOMETRICS
Identify publication trends, explore co-citations, map scientific domains, etc. |
 VOICE OF THE CUSTOMER VOICE OF THE CUSTOMER
Analyze customers’ feedback about their experiences with products or services. |
 MEDIA FRAMING ANALYSIS MEDIA FRAMING ANALYSIS
See how a given issue is being represented in media. |
|
Mixing GIS and Text Analytics for Better Insight |
 CORPORATE SOCIAL RESPONSIBILITY RESEARCH CORPORATE SOCIAL RESPONSIBILITY RESEARCH
CSR Literature Review Using QDA Miner and WordStat |
 CONTENT ANALYSIS IN POLITICAL SCIENCE CONTENT ANALYSIS IN POLITICAL SCIENCE
Learn how to apply automated content analysis across a diverse set of texts in political science |
 SOCIAL MEDIA CONTENT ANALYSIS SOCIAL MEDIA CONTENT ANALYSIS
A number of key features in QDA Miner and WordStat are effective when analyzing social media data |
|
HR professionals can use text analytics to analyze exit interviews, employee performance reviews, job applications, etc. |
 TEXT ANALYTICS ADDS VALUE TO NPS TEXT ANALYTICS ADDS VALUE TO NPS
Text Analytics can help you deal with all the why’s that NPS doesn’t show. |
 GEOSPATIAL INTELLIGENCE MEETS TEXT ANALYTICS
GEOSPATIAL INTELLIGENCE MEETS TEXT ANALYTICS TEXT ANALYTICS FOR HUMAN RESOURCE PROFESSIONALS
TEXT ANALYTICS FOR HUMAN RESOURCE PROFESSIONALS© All rights reserved Provalis Research 2025
WordStat is a flexible and easy-to-use text analysis software – whether you need text mining tools for fast extraction of themes and trends, or careful and precise measurement with state-of-the-art quantitative content analysis tools.