MODEL SPECIFICATION
- Use the SEM Builder or command language
- SEM Builder uses standard path diagrams
- Command language is a natural variation on path diagrams
- Group estimation is as easy as adding group(sex). Also easily add or relax constraints—ginvariant(mcoef) constrains all coefficients in the measurement model to be equal across groups. Or add paths for some groups but not others.
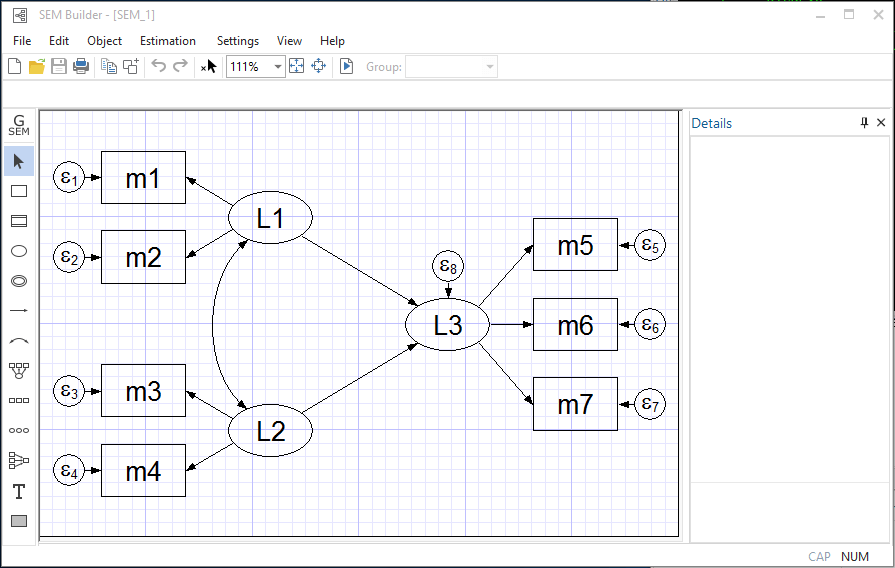
SEM BUILDER
- Drag, drop, and connect to create path diagrams
- Estimate models from path diagrams
- Display results on the path diagram
- Save and modify diagrams
- Tools to create measurement and regression components
- Set constant and equality constraints by clicking
- Complete control of how your diagrams look
CLASSES OF MODELS FOR LINEAR SEM
- Linear regression
- Multivariate regression
- Path analysis
- Mediation analysis
- Measurement models
- Confirmatory factor analysis (CFA)
- Multiple indicators and multiple causes (MIMIC) models
- Latent growth curve models
- Hierarchical CFA
- Correlated uniqueness models
- Arbitrary structural equation models
ADDITIONAL CLASSES OF MODELS FOR GENERALIZED SEM
- Generalized linear models
- Item response theory models
- Measurement models with binary, count, and ordinal measurements
- Multilevel CFA models
- Multilevel mixed-effects models
- Latent growth curve models with generalized-linear responses
- Multilevel mediation models
- Latent class analysis (LCA)
- Selection models
- with random intercepts and slopes
- with binary, count, and ordinal outcomes
- Endogenous treatment-effect models
- Any multilevel structural equation models with generalized-linear responses
STRUCTURAL EQUATION MODELS WITH SURVIVAL OUTCOMES
- Latent predictors of survival outcomes
- Path models, growth curve models, and more
- Weibull, exponential, lognormal, loglogistic, or gamma models
- Survival outcomes with other outcomes
LINEAR AND GENERALIZED-LINEAR RESPONSES
- Models for continuous, binary, count, ordinal, and nominal outcomes
- Thirteen distribution families
- Gaussian
- Bernoulli
- Binomial
- Poisson
- Negative binomial
- Ordinal
- Multinomial
- Beta
- Exponential
- Gamma
- Lognormal
- Loglogistic
- Weibull
- Five links
- Identity
- Log
- Logit
- Probit
- Cloglog
- Support for common regression models: linear, logistic, probit, ordered logit, ordered probit, Poisson, multinomial logistic, tobit, interval measurements, and more
MULTILEVEL MODELS
- Two-, three-, and higher-level structural equation models
- Multilevel mixed-effects models
- Random intercepts and random slopes
- Crossed and nested random effects
ESTIMATION METHODS FOR LINEAR SEM
- ML—maximum likelihood
- MLMV—maximum likelihood for missing values; sometimes called FIML
- ADF—asymptotic distribution free, meaning GMM (generalized method of moments) using ADF weighting matrix
ESTIMATION METHODS FOR GENERALIZED SEM
- Maximum likelihood
- Mean-variance or mode-curvature adaptive Gauss–Hermite quadrature
- Nonadaptive Gauss–Hermite quadrature
- Laplace approximation
STANDARD-ERROR METHODS
- OIM—observed information matrix
- EIM—expected information matrix
- OPG—outer product of gradients
- Satorra—Bentler estimator
- Robust—distribution-free linearized estimator
- Cluster–robust—robust adjusting for correlation within groups of observations
- Bootstrap—nonparametric bootstrap and clustered bootstrap
- Jackknife—delete-one, delete-n, and clustered jackknife
SURVEY SUPPORT FOR LINEAR SEM AND GENERALIZED SEM
- Sampling weights and stage-level weights
- Stratification and poststratification
- Clustered sampling at one or more levels
POSTESTIMATION SELECTOR
- View and run all postestimation features for your command
- Automatically updated as estimation commands are run
SUMMARY STATISTICS DATA (SSD)
- Fit linear SEMs on observed or summary (SSD) data
- Fit models on covariances or correlations and optionally variances and means
- SSD may be group specific
- Easily create and manage SSDs
- Build SSDs from original (raw) data for distribution or publication
- Automatic corruption/error checking and repairing
- Electronic signatures
STARTING VALUES
- Automatic
- May specify for some or all parameters
- Grid search available
- May fit one model, subset or superset, and use fitted values for another model
© Copyright 1996–2024 StataCorp LLC. All rights reserved.
IDENTIFICATION
- Automatic normalization (anchoring) constraints provide scale for latent variables; may be overridden
RELIABILITY
- May specify fraction of variance not due to measurement error
DIRECT AND INDIRECT EFFECTS FOR LINEAR SEM
- Confidence intervals
- Unstandardized or standardized units
OVERALL GOODNESS-OF-FIT STATISTICS FOR LINEAR SEM
- Model vs. saturated
- Baseline vs. saturated
- RMSEA, root mean squared error of approximation
- AIC, Akaike’s information criterion
- BIC, Bayesian information criterion
- CFI, comparative fit index
- TLI, Tucker–Lewis index, a.k.a. nonnormed fit index
- SRMR, standardized root mean squared residual
- CD, coefficient of determination
EQUATION-LEVEL GOODNESS-OF-FIT STATISTICS FOR LINEAR SEM
- R-squared
- Equation-level variance decomposition
- Bentler–Raykov squared multiple-correlation coefficient
GROUP-LEVEL GOODNESS-OF-FIT STATISTICS FOR LINEAR SEM
- SRMR
- CD
- Model vs. saturated chi-squared contribution
RESIDUAL ANALYSIS FOR LINEAR SEM
- Mean residuals
- Variance and covariance residuals
- Raw, normalized, and standardized values available
PARAMETER TESTS
- Modification indices
- Wald tests
- Score tests
- Likelihood-ratio tests
- Easy to specify single or joint custom tests for omitted paths, included paths, and relaxing constraints
- Linear and nonlinear tests of estimated parameters
- Tests may be specified in standardized or unstandardized parameter units
GROUP-LEVEL PARAMETER TESTS
- Group invariance by parameter class or user specified
LINEAR AND NONLINEAR COMBINATIONS OF ESTIMATED PARAMETERS
- Confidence intervals
- Unstandardized or standardized units
ASSESS NONRECURSIVE SYSTEM STABILITY
PREDICTIONS FOR LINEAR SEM
- Observed endogenous variables
- Latent endogenous variables
- Latent variables (factor scores)
- Equation-level first derivatives
- In- and out-of-sample prediction; may estimate on one sample and form predictions in another
PREDICTIONS FOR GENERALIZED SEM
- Means of observed endogenous variables—probabilities for 0/1 outcomes, mean counts, etc.
- Linear predictions of observed endogenous variables
- Latent variables using empirical Bayes means and modes
- Standard errors of empirical Bayes means and modes
- Observed endogenous variables with and without predictions of latent variables
- Density function
- Distribution function
- Survivor function
- Predict observed endogenous variables marginally with respect to latent variables
- User-defined nonlinear predictions
RESULTS
- May be used with postestimation features
- May be saved to disk for restoration and use later
- Displayed in standardized or unstandardized units
- Optionally display results in Bentler–Weeks form
- Optionally display results in exponentiated form as odds ratios, incidence rate ratios, and relative risk ratios
- All results accessible for community-contributed programs
FACTOR VARIABLES WITH GENERALIZED SEM
- Automatically create indicators based on categorical variables
- Form interactions among discrete and continuous variables
- Include polynomial terms
- Perform contrasts of categories/levels
MARGINAL ANALYSIS
- Estimated marginal means
- Marginal and partial effects
- Average marginal and partial effects
- Least-squares means
- Predictive margins
- Adjusted predictions, means, and effects
- Works with multiple outcomes simultaneously
- Integrates over latent variables
- Contrasts of margins
- Pairwise comparisons of margins
- Profile plots
- Graphs of margins and marginal effects
CONTRASTS FOR GENERALIZED SEM
- Analysis of main effects, simple effects, interaction effects, partial interaction effects, and nested effects
- Comparisons against reference groups, of adjacent levels, or against the grand mean
- Orthogonal polynomials
- Helmert contrasts
- Custom contrasts
- ANOVA-style tests
- Contrasts of nonlinear responses
- Multiple-comparison adjustments
- Balanced and unbalanced data
- Contrasts of means, intercepts, and slopes
- Graphs of contrasts
- Interaction plots
PAIRWISE COMPARISONS FOR GENERALIZED SEM
- Compare estimated means, intercepts, and slopes
- Compare marginal means, intercepts, and slopes
- Balanced and unbalanced data
- Nonlinear responses
- Multiple-comparison adjustments: Bonferroni, Sidak, Scheffe, Tukey HSD, Duncan, and Student–Newman–Keuls adjustments
- Group comparisons that are significant
- Graphs of pairwise comparisons